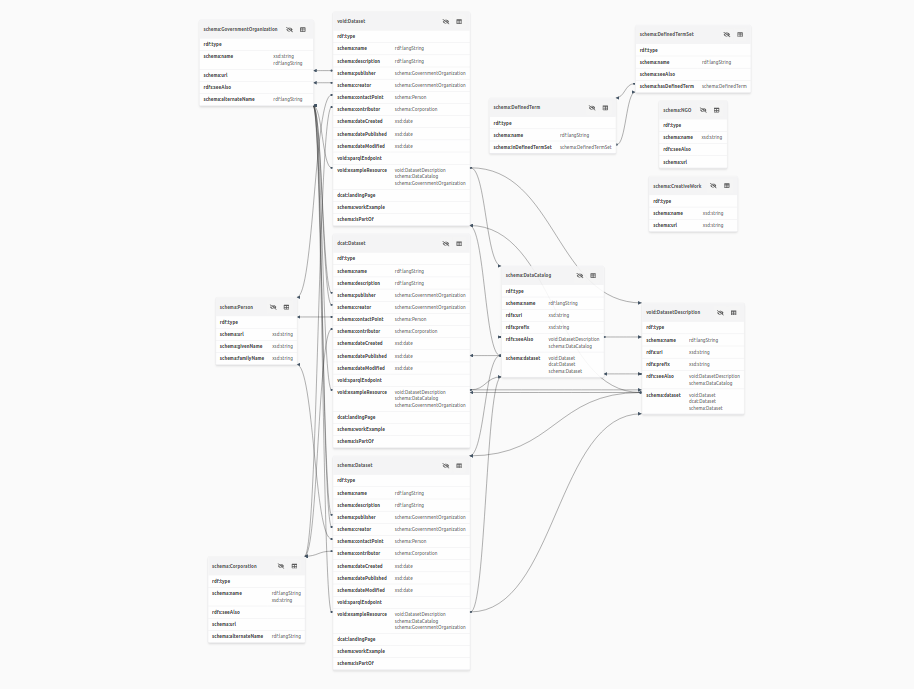
Data model for Zürich datasets¶
The Zürich Statistical Office collects data on the city and its residents. This data is published as Linked Data.
In this tutorial, we will explain the linked data model behind it. Mainly, we will guide you through the data structure. The tutorial will show you available datasets, and the shape they take. We will look into queries explaining the data structure as well as available dimensions.
SPARQL endpoint¶
Data by the Zürich Statistical Office is published as Linked Data. It can be accessed with SPARQL queries. You can send queries using HTTP requests. The API endpoint is https://ld.stadt-zuerich.ch/query.
We use the SPARQL kernel in a jupyter notebook to communicate with the database (you may need to configure this via menu Kernel -> Change kernel -> SPARQL). First, let's configure the endpoint.
#Params
%endpoint https://ld.stadt-zuerich.ch/query
%auth basic public public
%display table
%show 50
Graphs¶
One endpoint can contain multiple named graphs.
You can see what graphs are available using WHERE and GRAPH statements.
# List graphs in endpoint
SELECT DISTINCT ?graphs
WHERE {
GRAPH ?graphs {
?s ?p ?o;
}
}
These graphs have potentilly nothing in common, they are simply stored in the same database.
Here, we have one endpoint storing information on subject as diverse as the train timetable, electricity prices, or animal diseases:
- trains timetable (https://lindas.admin.ch/sbb/setactual)
- electricity prices (https://lindas.admin.ch/elcom/electricityprice)
- animal diseases (https://linked.opendata.swiss/fsvo/animalpest)
All those graphs can be accessed from the same SPARQL endpoint.
Graph by Zürich Statistical Office¶
Datasets from the Zürich Statistical Office are published in the following named graph: <https://lindas.admin.ch/stadtzuerich/stat>
You can limit your queries to one named graph using WHERE and FROM statements.
# List random triples in the graph
SELECT *
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {?s ?p ?o}
LIMIT 10
OFFSET 100
Data cubes¶
Datasets published by Zürich Statistial Office are stored as data cubes. Let's check the cube definition in its documentation:
Cube
Represents the entry point for a collection of observations, conforming to some common dimensional structure.
We can find all data cubes by defining <https://cube.link/Cube> as object.
# List all data cubes
SELECT ?cubes
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
?cubes a <https://cube.link/Cube> .
}
All cubes have the same data structure. This means we can write very similar queries to get data from different cubes.
Data cubes have the following properties:
# Cube properties
SELECT DISTINCT ?properties
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
?s a <https://cube.link/Cube> ;
?properties ?o.
}
Let's learn more about available data cubes. We can access cube description using <http://schema.org/name> property. We will also get its id using <http://schema.org/identifier>. By defining schema and cube as PREFIX, we can save some typing.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
SELECT *
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
?cube a cube:Cube ;
schema:name ?description ;
schema:identifier ?id .
}
You can see that some cubes have more than one description.
Observation set¶
Observations in data cubes are stored in observation set (<https://cube.link/observationSet>). Let's check the observationSet definition in its documentation:
observationSet
Connects a cube with a set of observations.
We can find all observations in a cube using cube:observationSet/cube:observation as predicate.
Let's query all observations in <https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> cube.
# List all observations in a cube
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
SELECT ?obs
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> a cube:Cube;
cube:observationSet/cube:observation ?obs.
}
LIMIT 10
We can count the number of observations using COUNT statement
# Count observations in a data cube
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
SELECT (COUNT(?obs) AS ?count)
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> a cube:Cube;
cube:observationSet/cube:observation ?obs.
# Equivalent to:
# cube:observationSet ?observationSet.
#?observationSet cube:observation ?obs.
}
So in BEW-HEL-SEX cube we have almost 10k observations about the population of Zürich!
Observations¶
Let's take a closer look at the observations. We can get all observation properties using this query:
# Observation properties
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
SELECT DISTINCT ?obsProperty
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
?dataset a cube:Cube;
cube:observationSet/cube:observation ?observation.
?observation ?obsProperty ?obsVal.
}
Quite a bit! Now, not every dataset will have all those properties.
Let's get a list of properties for the <https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> data cube. We will also get its labels using schema:name, and descrption using schema:description.
Since not all properties have a description, we will use the OPTIONAL statement to query it.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
SELECT DISTINCT ?obsProperty ?label ?description
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> a cube:Cube;
cube:observationSet/cube:observation ?observation.
?observation ?obsProperty ?obsVal.
?obsProperty schema:name ?label .
OPTIONAL {
?obsProperty schema:description ?description .
}
}
We can see that BEW-HEL-SEX data cube contains data on the population across:
- time (german: Zeit)
- place (german: Raum)
- gender (german: Geschlecht)
- origin (german: Heimatland)
Knowing properties, we can directlty query the measurements. Now, we are able to find the actual data: number of inhabitants across time, place, gender, and origin.
We will find the measurements using <https://ld.stadt-zuerich.ch/statistics/measure/BEW> as the observation's property. We will also the cube's dimensions using:
<https://ld.stadt-zuerich.ch/statistics/property/RAUM>for place<https://ld.stadt-zuerich.ch/statistics/property/TIME>for time<https://ld.stadt-zuerich.ch/statistics/property/HEL>for origin<https://ld.stadt-zuerich.ch/statistics/property/SEX>for gender
And again, making use of PREFIX makes the query more readable.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
SELECT ?time ?place ?origin ?gender ?count
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> a cube:Cube;
cube:observationSet/cube:observation ?obs.
?obs <https://ld.stadt-zuerich.ch/statistics/measure/BEW> ?count ;
property:RAUM ?place ;
property:TIME ?time ;
property:HEL ?origin ;
property:SEX ?gender .
}
LIMIT 10
To make the output more readable, let's replace the IRIs with the corresponding labels. This can be achieved by using schema:name for each property.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
SELECT ?time ?place ?origin ?gender ?count
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> a cube:Cube;
cube:observationSet/cube:observation ?obs.
?obs <https://ld.stadt-zuerich.ch/statistics/measure/BEW> ?count ;
property:RAUM/schema:name ?place ;
property:TIME ?time ;
property:HEL/schema:name ?origin ;
property:SEX/schema:name ?gender .
}
LIMIT 10
Volià! We now got all measurements across all dimensions in the BEW-ALT-SEX data cube. The data could be further refined, for example by filtering on gender or place.
Let's do the same exercise for the QMP-EIG-HAA-OBJ-ZIM data cube.
First, let's get observations' properties.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
SELECT DISTINCT ?obsProperty ?label ?description
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/QMP-EIG-HAA-OBJ-ZIM> a cube:Cube;
cube:observationSet/cube:observation ?observation.
?observation ?obsProperty ?obsVal.
?obsProperty schema:name ?label .
OPTIONAL {
?obsProperty schema:description ?description .
}
}
Now, let's use these properties to query the data.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
SELECT ?time ?place ?rooms ?ownership ?haa ?type ?price
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/QMP-EIG-HAA-OBJ-ZIM> a cube:Cube;
cube:observationSet/cube:observation ?obs .
?obs <https://ld.stadt-zuerich.ch/statistics/measure/QMP> ?price ;
property:TIME ?time ;
property:RAUM/schema:name ?place ;
property:ZIM/schema:name ?rooms ;
property:EIG/schema:name ?ownership ;
property:HAA/schema:name ?market ;
property:OBJ/schema:name ?type .
}
LIMIT 10
You can see that some prices come back as zero. Getting an appartment for free is extremely rare in Switzerland. That's presumably a data issue.
Let's remove those invalid observations using a FILTER statement.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
SELECT ?time ?place ?rooms ?ownership ?haa ?type ?price
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/QMP-EIG-HAA-OBJ-ZIM> a cube:Cube;
cube:observationSet/cube:observation ?obs .
?obs <https://ld.stadt-zuerich.ch/statistics/measure/QMP> ?price ;
property:TIME ?time ;
property:RAUM/schema:name ?place ;
property:ZIM/schema:name ?rooms ;
property:EIG/schema:name ?ownership ;
property:HAA/schema:name ?market ;
property:OBJ/schema:name ?type .
FILTER (?price > 0)
}
LIMIT 10
That's better!
Data slices¶
Thus far, we queried all observations from the data cube. Sometimes, you are interested in just some of the dimensions. You can aggregate the results using GROUP BY and SUM statements.
Let's find the total number of people in Zurich accross property:TIME. To do this, we sum the remaining dimensions:
property:RAUMproperty:HELproperty:SEX
This can be achieved by leaving them out of the GROUP BY statement. All unmentioned variables will be aggregated.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
SELECT ?time (SUM(?count) AS ?aggCount)
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> a cube:Cube;
cube:observationSet/cube:observation ?obs.
?obs <https://ld.stadt-zuerich.ch/statistics/measure/BEW> ?count ;
property:TIME ?time .
}
GROUP BY ?time
LIMIT 10
You can also filter the results to include only one dimension. This can be done by setting the object to the value you are interested in.
Let's get the number of female inhabitants over time. First, we will find IRIs for gender.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
SELECT DISTINCT ?genderIRI ?gender
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> a cube:Cube;
cube:observationSet/cube:observation ?obs.
?obs property:SEX ?genderIRI.
?obs property:SEX/schema:name ?gender .
}
<https://ld.stadt-zuerich.ch/statistics/code/SEX0002> stands for female (german weiblich). We will use it to filter observations for female only.
In SPARQL, this can be done by setting observation predicate to property:SEX, and its object to <https://ld.stadt-zuerich.ch/statistics/code/SEX0002>.
PREFIX schema: <http://schema.org/>
PREFIX cube: <https://cube.link/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
SELECT ?time ?place ?origin ?count
FROM <https://lindas.admin.ch/stadtzuerich/stat>
WHERE {
<https://ld.stadt-zuerich.ch/statistics/BEW-HEL-SEX> a cube:Cube;
cube:observationSet/cube:observation ?obs.
?obs <https://ld.stadt-zuerich.ch/statistics/measure/BEW> ?count ;
property:RAUM/schema:name ?place ;
property:TIME ?time ;
property:HEL/schema:name ?origin ;
property:SEX <https://ld.stadt-zuerich.ch/statistics/code/SEX0002> .
}
LIMIT 10
Volià, the number of female inhabitants across time, origin, and city district.
SPEX¶
There are many ways to learn about the structure of linked data. SPARQL queries may seem dense at first and may take some time to get you to the right place. However, as you get better with SPARQL, they are a great tool to slice data.
Another way to discover linked data is SPEX, a web based tool that visualizes the structure of a linked data source.
SPEX